2023-11-16 10:00:02 | 来源: 用户投稿
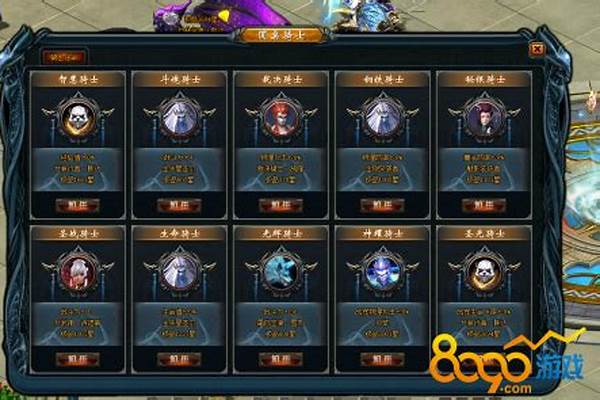
《魔域骑士》副本在哪里
在游戏《魔域骑士》中,副本是玩家提升实力、获取装备和材料的重要地点。玩家可以通过挑战副本获得丰厚奖励,提高自己在游戏中的竞争力。对于新手玩家来说,了解副本的位置和特点是非常重要的。
首先,魔域骑士中的副本分为普通副本和精英副本两种类型。普通副本主要用于获取基础装备和经验,而精英副本则提供更高级的装备和材料奖励,难度也相应更大。
普通副本通常位于游戏地图的各个区域,玩家可以通过点击地图上的相应位置进入挑战。在挑战前,玩家需要组建一个符合要求的队伍,包括角色的职业搭配、装备选择等方面的考量。
精英副本则通常隐藏在地图中的某些特定位置,玩家需要完成一定条件或者触发特定事件才能解锁挑战。这样的设计增加了游戏的探索性和挑战性,也丰富了游戏的可玩性。
除了地图中的副本外,部分副本也可以通过游戏内的任务系统或者活动活动入口直接进入挑战。这些副本通常会有一些特殊的规则和挑战要求,需要玩家结合自己的实力和队伍的特点来进行应对。
总的来说,在《魔域骑士》中,副本的位置分布较为广泛,玩家需要通过不断的探索和挑战来逐渐解锁和提升自己的实力。熟悉副本的位置和特点,合理安排队伍和装备,是玩家成功挑战副本并获取丰厚奖励的关键。同时,也希望玩家在游戏中能够享受到挑战副本的乐趣,不断提升自己的游戏技能和策略思维。
游戏资讯
手游排行榜
疯狂原始人
角色扮演奥特曼传奇英雄免费版
动作格斗组团来消除
休闲益智果冻块冲浪d
休闲益智航海贸易物语
模拟经营流星视频
影视播放漫芽糖简笔画
教育学习掌上答题
教育学习公牛智家
其他应用游戏专题
超级房车赛游戏08-26
王者荣耀手游08-26
休闲竞技手游08-26
三国手游08-26
奇葩游戏大全08-26